
Negli ultimi mesi abbiamo avuto l’opportunità di collaborare con un cliente multinazionale per implementare un sistema per il monitoraggio della sua complessa infrastruttura IT.
Grazie alle nostre precedenti esperienze, già dalla prima riunione siamo stati subito consapevoli delle esigenze che avremmo dovuto soddisfare.
Tra queste figurano principalmente la prevenzione dei guasti e la riduzione dei tempi di inattività (downtime), con conseguenti perdite economiche. L’obiettivo andava raggiunto rilevando e segnalando in tempo reale sovraccarichi o malfunzionamenti che provocavano rallentamenti o interruzioni nelle operazioni aziendali e nelle catene di produzione industriale. Altre esigenze presentate erano: la centralizzazione del monitoraggio di tutti i componenti eterogenei dell’infrastruttura, per averne una visione unificata; l’ottimizzazione delle prestazioni, mediante l’analisi delle metriche e l’individuazione dei colli di bottiglia; la creazione di una base tecnologica per l’intervento proattivo e automatizzato del sistema, per realizzare procedure di self-healing.
La sfida prevedeva quindi l’implementazione di una soluzione di Observability per i data center geograficamente distribuiti del cliente. Situati in due diverse località, i data center comprendono decine di server che vanno da sistemi piuttosto obsoleti come Slackware 8 a piattaforme moderne come Ubuntu 22 e Windows 11. I server si differenziano anche per funzionalità implementate: database, web server, firewall e macchine per il controllo di apparecchiature industriali.
Approccio e risultati
Per rispondere alle esigenze del cliente, abbiamo condotto un’indagine approfondita dell’infrastruttura e deciso di basare la nostra soluzione su Prometheus, Grafana e Ansible, strumenti che conosciamo e siamo in grado di personalizzare a fondo. Ecco come abbiamo operato:
- Distribuzione e Configurazione
- È stato configurato un server di monitoraggio centralizzato per ospitare Prometheus e Grafana.
- Abbiamo utilizzato Ansible per automatizzare il provisioning, garantendo configurazioni centralizzate e ripetibili.
- Raccolta di Metriche
- Abbiamo implementato gli exporter standard per raccogliere metriche dai sistemi operativi, dai database e dai web server.
- Per i sistemi più vecchi che non supportano le dipendenze moderne, abbiamo sviluppato exporter personalizzati in Python.
- Osservabilità su Misura per i Processi Industriali
- Sono state integrate metriche personalizzate per monitorare e verificare i processi che controllano le apparecchiature industriali, garantendo il funzionamento continuo dei sistemi critici.
- Allarmi e notifiche
- Sono stati configurati allarmi per monitorare le metriche chiave.
- Le notifiche sono state integrate con Microsoft Teams e email, per garantire interventi rapidi in caso di criticità.
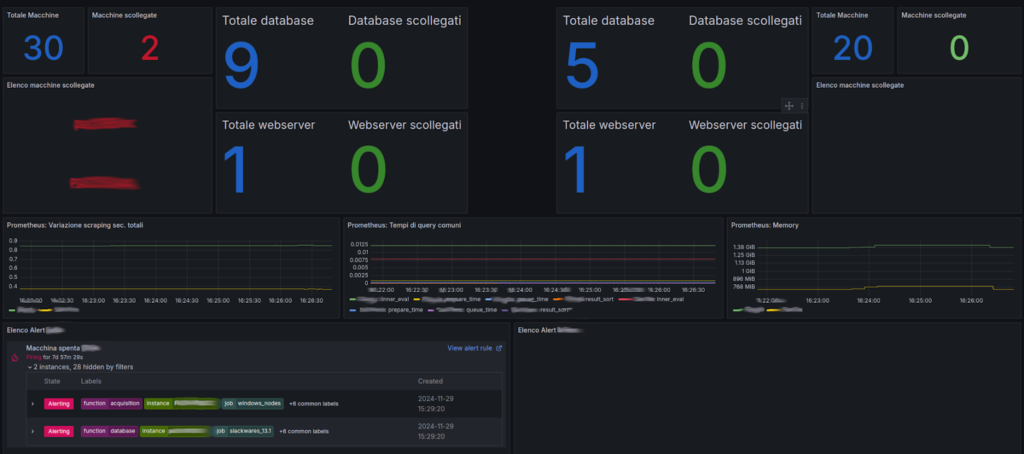
Questa soluzione su misura ha permesso al nostro cliente di ottenere insight in tempo reale e un controllo completo sulla sua infrastruttura. Per noi, questo progetto è stata anche un’opportunità straordinaria per ampliare le nostre competenze e padroneggiare: gli Exporter di Prometheus con lo sviluppo di soluzioni dedicate, il Dashboarding con Grafana utilizzando query avanzate e relative visualizzazioni, e Sistemi di alerting complessi legati a processi reali.
Conclusione
Il progetto è stato una prova concreta del nostro impegno nel risolvere sfide complesse e fornire soluzioni robuste e scalabili. Siamo orgogliosi di aver non solo soddisfatto, ma superato le aspettative, permettendo al nostro cliente di raggiungere un livello di osservabilità senza precedenti per i suoi sistemi critici.
Hai una sfida complessa per la tua infrastruttura? Risolviamola insieme!